ML-依照目標target,(未來以「target」) 是否有標籤label,(未來以「label」),可以區分為監督式學習supervised-learning(有標籤),未來以「supervised-learning」,昨日提供的身高體重範例即是而讓機器猜出是男是女(即是label)亦即 supervised-learning。
非監督式學習unsupervised-learning,對於target並無標籤標示,(未來以「unsupervised-learning」)。
還有一種是有記錄狀態,報酬、回饋等稱之強化學習reinforcement learning,(未來以「reinforcement learning」)
,例如:教機器下圍棋,在下每一步前先保留狀態,看這一步走的結果是得到獎賞(ex.吃掉黑子)或是得到惩罰(ex.被對手吃掉),再根據這一步驟的狀態與報酬決定下一步要怎麼走。
supervised-learning:依照target目標是連續
(continuous)或離散(discrete)可以區分為迴歸(regression),(未來以「regression」)-continuous和分類(classification),未來以「classification」-discrete。
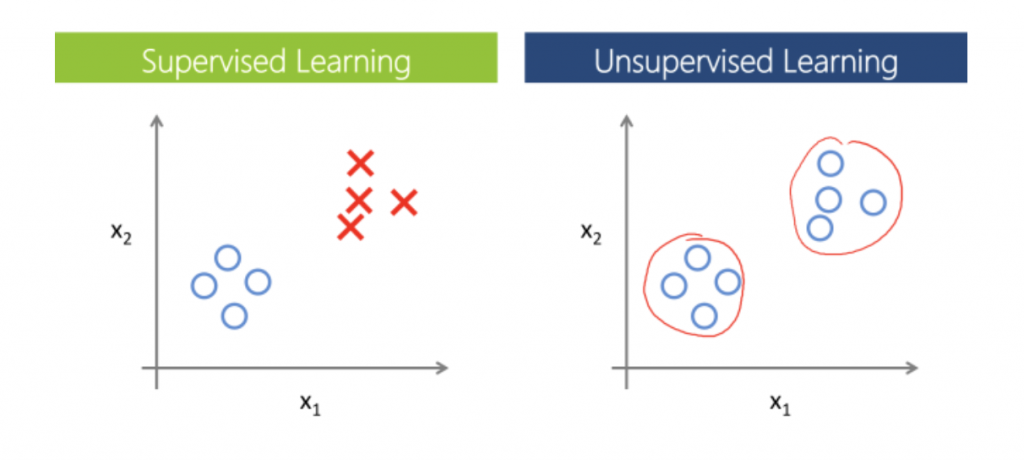
[圖片參考:](https://lakshaysuri.wordpress.com/2017/03/19/machine-learning-supervised-vs-unsupervised-learning/)
上圖的圈圈與叉叉代表兩種分類。
regression:簡單迴歸simple regression,未來以「simple regression」,線性迴歸linear regression,未來以「linear regression」,多元迴歸multiple regression,未「multiple regression」,多項式迴歸polynomial regression,未來以「polynomial regression」
classification:羅吉斯迴歸,logistic regression,未來以「logistic regression」又稱二元迴歸,雖名為迴歸實際是分類法,支持向量機Support Vector Machine SVM,(未來以「SVM」),決策樹decision tree(未來以「decision tree」),隨機森林random forest,(未來以「random forest」),天真貝式Navie Bayes(未來以「Navie Bayes」):常用於分類垃圾郵件。K最近鄰法K-Nearest-Neighboors ,(未來以「KNN」 )等。
dimensionality reduction:主成份分析Principal Component Analysis,PCA(未來以「PCA」)(提取特徵值,特徵向量)
clustering analysis:依照不同類型的分群方式, 如:階層,球心。而有K-means質心分群法,(未來以「K-means」),Hierarchy Clustering階層式分群法,(未來以「Hierarchy
Clustering」),DBSCAN Density-Based Spatial Clustering of Applications with Noise 球心式分群法,未「 DBSCAN」
day3說的男生與女生身高體重的範例,即是logistic regression。


 iThome鐵人賽
iThome鐵人賽